Aggregating and analyzing data with dplyr
Data Carpentry contributors
Learning Objectives
- Describe what the dplyr package in R is used for.
- Apply common dplyr functions to manipulate data in R.
- Use the ‘pipe’ operator to link together a sequence of functions.
- Use the ‘mutate’ function to create new columns of data.
- Use the ‘split-apply-combine’ concept to summarise data.
Bracket subsetting is handy, but it can be cumbersome and difficult to read, especially for complicated operations.
Enter dplyr.
dplyr is a package for making data manipulation easier.
Packages in R are basically sets of additional functions that let you do more stuff in R. The functions we’ve been using, like str(), come built into R; packages give you access to more functions. You need to install a package and then load it to be able to use it.
install.packages("dplyr") ## installYou might get asked to choose a CRAN mirror – this is basically asking you to choose a site to download the package from. The choice doesn’t matter too much; I’d recommend choosing the RStudio mirror.
library("dplyr") ## loadYou only need to install a package once per computer, but you need to load it every time you open a new R session and want to use that package.
Selecting columns and filtering rows with dplyr
We’re going to learn some of the most common dplyr functions: select(), filter(), mutate(), group_by(), and summarize().
To select columns of a data frame, use select(). The first argument to this function is the data frame (metadata), and the subsequent arguments are the columns to keep.
select(metadata, sample, clade, cit, genome_size)To choose rows, use filter():
filter(metadata, cit == "plus")## sample generation clade strain cit run genome_size
## 1 ZDB564 31500 Cit+ REL606 plus SRR098289 4.74
## 2 ZDB172 32000 Cit+ REL606 plus SRR098042 4.77
## 3 ZDB143 32500 Cit+ REL606 plus SRR098040 4.79
## 4 CZB152 33000 Cit+ REL606 plus SRR097977 4.80
## 5 CZB154 33000 Cit+ REL606 plus SRR098026 4.76
## 6 ZDB87 34000 C2 REL606 plus SRR098035 4.75
## 7 ZDB96 36000 Cit+ REL606 plus SRR098036 4.74
## 8 ZDB107 38000 Cit+ REL606 plus SRR098038 4.79
## 9 REL10979 40000 Cit+ REL606 plus SRR098029 4.78Pipes
But what if you wanted to select and filter? There are three ways to do this: use intermediate steps, nested functions, or pipes. With the intermediate steps, you essentially create a temporary data frame and use that as input to the next function. This can clutter up your workspace with lots of objects. You can also nest functions (i.e. one function inside of another). This is handy, but can be difficult to read if too many functions are nested as the process from inside out. The last option, pipes, are a fairly recent addition to R. Pipes let you take the output of one function and send it directly to the next, which is useful when you need to many things to the same data set. Pipes in R look like %>% and are made available via the magrittr package installed as part of dplyr.
metadata %>%
filter(cit == "plus") %>%
select(sample, generation, clade)## sample generation clade
## 1 ZDB564 31500 Cit+
## 2 ZDB172 32000 Cit+
## 3 ZDB143 32500 Cit+
## 4 CZB152 33000 Cit+
## 5 CZB154 33000 Cit+
## 6 ZDB87 34000 C2
## 7 ZDB96 36000 Cit+
## 8 ZDB107 38000 Cit+
## 9 REL10979 40000 Cit+In the above we use the pipe to send the metadata data set first through filter, to keep rows where cit was equal to ‘plus’, and then through select to keep the sample and generation and clade columns. When the data frame is being passed to the filter() and select() functions through a pipe, we don’t need to include it as an argument to these functions anymore.
If we wanted to create a new object with this smaller version of the data we could do so by assigning it a new name:
meta_citplus <- metadata %>%
filter(cit == "plus") %>%
select(sample, generation, clade)
meta_citplus## sample generation clade
## 1 ZDB564 31500 Cit+
## 2 ZDB172 32000 Cit+
## 3 ZDB143 32500 Cit+
## 4 CZB152 33000 Cit+
## 5 CZB154 33000 Cit+
## 6 ZDB87 34000 C2
## 7 ZDB96 36000 Cit+
## 8 ZDB107 38000 Cit+
## 9 REL10979 40000 Cit+Challenge
Using pipes, subset the data to include rows where the clade is ‘Cit+’. Retain columns
sample,cit, andgenome_size.
Solution
metadata %>%
filter(clade == "Cit+") %>%
select(sample, cit, genome_size)Mutate
Frequently you’ll want to create new columns based on the values in existing columns, for example to do unit conversions or find the ratio of values in two columns. For this we’ll use mutate().
To create a new column of genome size in bp:
metadata %>%
mutate(genome_bp = genome_size * 1e6)If this runs off your screen and you just want to see the first few rows, you can use a pipe to view the head() of the data (pipes work with non-dplyr functions too, as long as the dplyr or magrittr packages are loaded).
metadata %>%
mutate(genome_bp = genome_size * 1e6) %>%
head()The first row has a NA value for clade, so if we wanted to remove those we could insert a filter() in this chain, using a built-in R function to identify NA values:
metadata %>%
mutate(genome_bp = genome_size * 1e6) %>%
filter(!is.na(clade)) %>%
headis.na() is a function that determines whether something is or is not an NA. The ! symbol negates it, so we’re asking for everything that is not an NA.
Split-apply-combine data analysis and the summarize() function
Many data analysis tasks can be approached using the “split-apply-combine” paradigm: split the data into groups, apply some analysis to each group, and then combine the results.
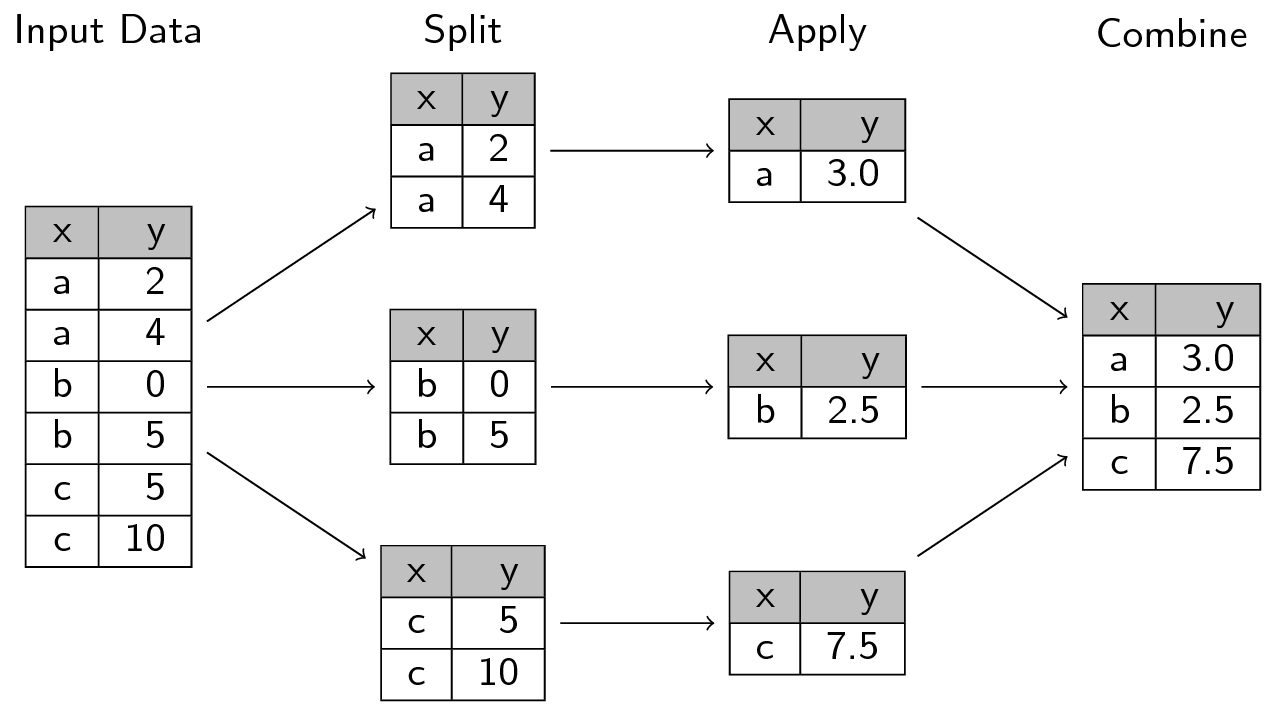
Split apply combine
dplyr makes this very easy through the use of the group_by() function, which splits the data into groups. When the data is grouped in this way summarize() can be used to collapse each group into a single-row summary. summarize() does this by applying an aggregating or summary function to each group. For example, if we wanted to group by citrate-using mutant status and find the number of rows of data for each status, we would do:
metadata %>%
group_by(cit) %>%
summarize(n())## # A tibble: 3 x 2
## cit `n()`
## <fctr> <int>
## 1 minus 9
## 2 plus 9
## 3 unknown 12Here the summary function used was n() to find the count for each group.
We can also apply many other functions to individual columns to get other summary statistics. For example, there are built-in functions in R like mean, median, min, and max.
Note: By default, all R functions operating on vectors that contains missing data will return NA.It’s a way to make sure that users know they have missing data, and make a conscious decision on how to deal with it. Whendealing with simple statistics like the mean, the easiest way to ignore NA (the missing data) is to use the argument na.rm=TRUE (rm stands for remove).
So to view mean genome_size by mutant status:
metadata %>%
group_by(cit) %>%
summarize(mean_size = mean(genome_size, na.rm = TRUE))## # A tibble: 3 x 2
## cit mean_size
## <fctr> <dbl>
## 1 minus 4.614444
## 2 plus 4.768889
## 3 unknown 4.619167You can group by multiple columns too:
metadata %>%
group_by(cit, clade) %>%
summarize(mean_size = mean(genome_size, na.rm = TRUE))## # A tibble: 13 x 3
## # Groups: cit [?]
## cit clade mean_size
## <fctr> <fctr> <dbl>
## 1 minus C1 4.606667
## 2 minus C2 4.625000
## 3 minus C3 4.610000
## 4 minus Cit+ 4.600000
## 5 plus C2 4.750000
## 6 plus Cit+ 4.771250
## 7 unknown (C1,C2) 4.620000
## 8 unknown C1 4.630000
## 9 unknown C2 4.620000
## 10 unknown C3 4.590000
## 11 unknown UC 4.625000
## 12 unknown unknown 4.615000
## 13 unknown <NA> 4.620000Looks like for one of these clones, the clade is missing. We could then discard those rows using filter():
metadata %>%
group_by(cit, clade) %>%
summarize(mean_size = mean(genome_size, na.rm = TRUE)) %>%
filter(!is.na(clade))All of a sudden this isn’t running off the screen anymore. That’s because dplyr has changed our data.frame to a tbl_df. This is a data structure that’s very similar to a data frame; for our purposes the only difference is that it won’t automatically show tons of data going off the screen.
You can also summarize multiple variables at the same time:
metadata %>%
group_by(cit, clade) %>%
summarize(mean_size = mean(genome_size, na.rm = TRUE),
min_generation = min(generation))Much of this lesson was copied or adapted from Jeff Hollister’s materials
Data Carpentry,
2017. License. Contributing.
Questions? Feedback?
Please file
an issue on GitHub.
On
Twitter: @datacarpentry